How we consistently deliver the best possible updates to our maps
We have made great strides toward accomplishing our goal of providing the best location content available on a worldwide scale – but our work at HERE goes far beyond just maps.
I thought about this recently; our team is so deeply involved with location data technology that it can be difficult to grasp what actually goes into this type of work. For many people, the data is simply ‘there' – the maps, the traffic, the addresses, etc. are all there, so no one needs to spend much time considering the source, the quality, or the potential usefulness of the aforementioned data.
However, the source and the quality are critical. If we are to build future services and applications based on location data, then the time to be certain that data is of the highest quality possible is right now. To better understand how our platform enables services for the future, it’s helpful to take a step back and understand what we are already doing.
In the simplest of terms, we collect data
Data is collected from a variety of sources, and we continuously monitor those sources to derive updates for our maps in real-time. That’s a very fundamental thing that we do.
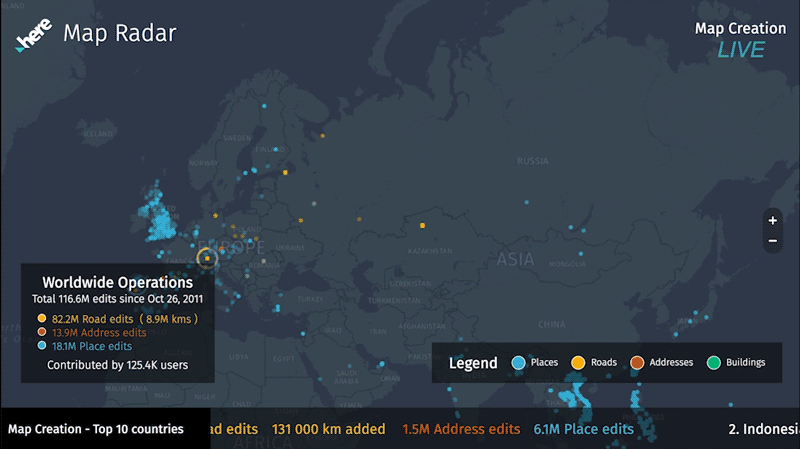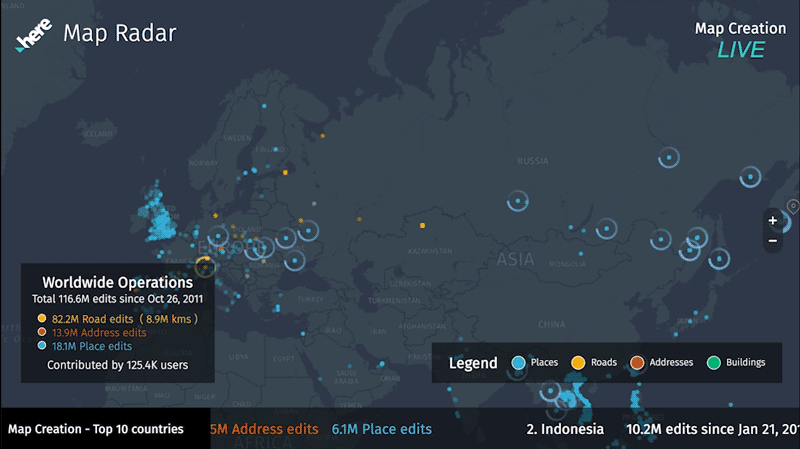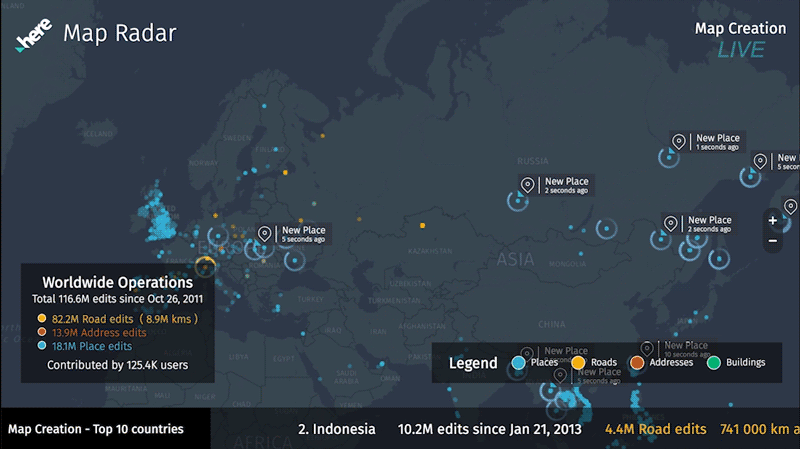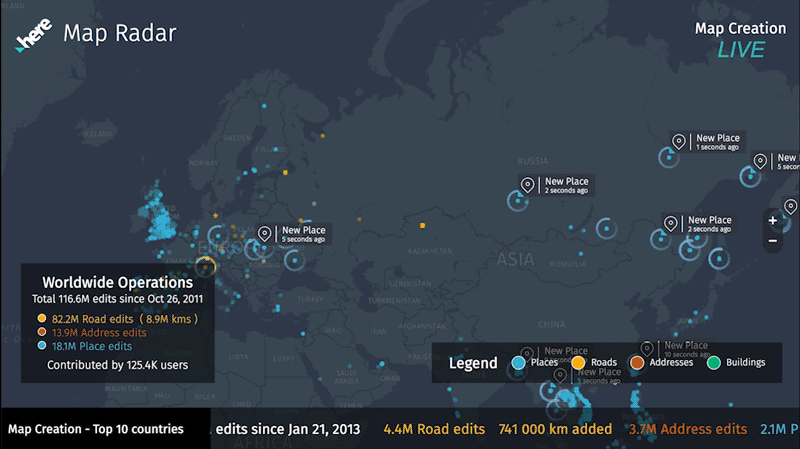
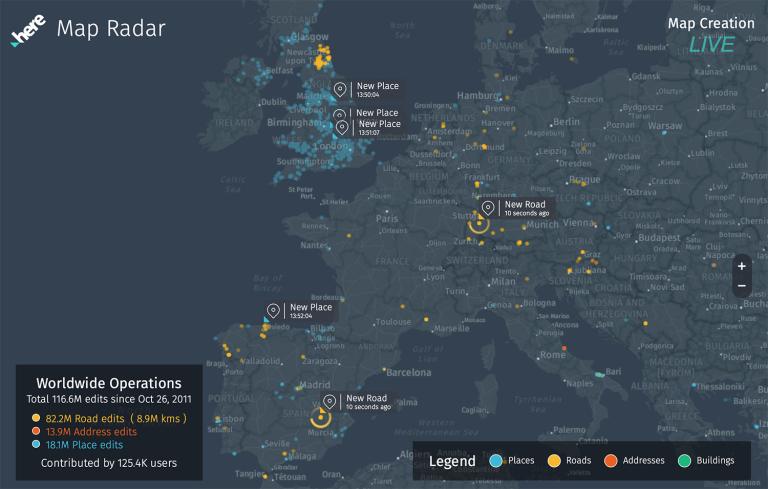
We receive data from our global mapping community through Map Creator. This approach allows anyone to go in and propose map changes. We have extremely active communities of creators all over the world.
We also receive data from cars, which is complementary to the mapping communities. Cars send us probe and sensor data in the form of all the details a car can understand about itself, the environment around it, and its location. It’s complementary to the mapping community because cars cannot send us updates for new roads or addresses like a human can.
We are provided with rich data from companies, customers, data partners, and social media platforms. Each provides data in the form of addresses for businesses, when and where people conduct transactions, or when they check in to share their status (anonymously, of course), giving us an indicator about the relevance of that data for how we can best put it to use.
Local governments and infrastructures are embracing an open data approach, where they provide data-windows into public transit, construction, zoning and address changes, and more. We partner with companies and organizations across multiple industries who share similar information like aerial photography, which we can employ machine learning to discover buildings and roads that haven’t previously been identified.
Are you starting to sense the problem that comes into play?

Organizing this beautiful content-verse
We have all of these beautiful sources of content, but they can be a challenge to read. Is the data organized left-to-right, or top-to-bottom? What are the characters and the rules of the language? How is it encoded? It’s just raw data. How do we turn it into reliable information?
I mention reliable information because not all data is objective. We must ask what aspects of the data can be trusted outright, versus what data points need to be reviewed or confirmed. It’s nice to have these millions upon millions of data updates every day, but that data must be moderated. This is where we use a combination of human-driven and machine-driven processes to absorb, interpret, and validate that data such that we can generate reliable map updates in real time.
For an example of how we moderate data, a map creator might report that a restaurant doesn’t exist anymore. We can compare that information with other sources. Has anyone on a social media platform checked in there? Does the restaurant have a webpage that has been updated?
Alternatively, machine learning may detect from an aerial image that a new road is being built. Our approach cross-checks that information with probe data from cars to see if someone is driving through that space. We look at the open portal information from the city to see if that road is part of their plan, and we can go further to check with the post office to see what those addresses will be.
Of course, it’s possible that the AI involved in detecting and cross-checking new data points to confirm their validity may run into trouble. In those cases, there is a human in the loop to make more difficult, human-driven determinations. However, making the process autonomous is the only way to make it scale for a global demand.
The best possible information gets delivered to our maps
In this data lifecycle, we use machine learning to cross-check millions of units of information every day. This process of moderating updates is scalable, it happens continuously, and it happens in real time.
Now we have created a real-time map that is being perpetually updated with highly reliable information from multiple sources. The accuracy and freshness of our maps is of great value to us, and it’s of great value to those that use our location data as tool for their applications. One of the chief applications for these updates will be when autonomous cars come to the roadways. Real-time, highly accurate updates are necessary to autonomous cars the same way that peripheral vision is important to human drivers.
It’s an essential part of our platform: we collect various forms of data from companies like BMW, Audi, Daimler, Microsoft, Garmin, Facebook etc. and we provide unified data back out to those companies (and platforms like SAP and AWS) so that everyone can utilize it to build their own tools.
Like with the local governments that provide open data, each of the companies that use our data can adapt it to their own custom format. Two different car companies that use our map data can individually make their maps, the UX/UI, and all the branding completely their own. They can use that data to provide their drivers with custom services, and the underlying information is always up-to-date since it comes from our systems.
So this is what we do. In a way, we’re working as a mapping consortium to build up a platform that anyone can use, so we can support our customers in building the best possible solutions. By making sure that the data is accurate and unified, we gain certainty that the next generation of services are being built with tools that will sustain them well into the future.

Have your say
Sign up for our newsletter
Why sign up:
- Latest offers and discounts
- Tailored content delivered weekly
- Exclusive events
- One click to unsubscribe